
This is first part of my “Improve Solr Search” series. I will cover here how Solr analyzers works while indexing and querying the content and how you can improve it.
Prerequisite: Use Correct Field Types in Index Configuration
If you created your custom search index from the default Sitecore web index, your search may not use all the algorithms described below, for stop-words, synonyms, stemming, etc. It happens because Sitecore may not use field type that you configured in Solr. To address this issue you should change in Solr index scheme, type attribute of default dynamic field for English texts from:
<dynamicField name="*_t_en" type="text_general" indexed="true" stored="true"/>
to
<dynamicField name="*_t_en" type="text_en" indexed="true" stored="true"/>
Then in index configuration in Sitecore make sure your field uses proper type:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<fieldMap type="Sitecore.ContentSearch.SolrProvider.SolrFieldMap, Sitecore.ContentSearch.SolrProvider"> <typeMatches hint="raw:AddTypeMatch"> ... <typeMatch typeName="text" type="System.String" fieldNameFormat="{0}_t" cultureFormat="_{1}" settingType="Sitecore.ContentSearch.SolrProvider.SolrSearchFieldConfiguration, Sitecore.ContentSearch.SolrProvider" /> <typeMatches> </fieldMap> <documentOptions type="Sitecore.ContentSearch.SolrProvider.SolrDocumentBuilderOptions, Sitecore.ContentSearch.SolrProvider"> ... <fields hint="raw:AddComputedIndexField"> <field fieldName="description" returnType="text">Feature.Search.MyDescriptionComputedField, Feature.Search</field> <field fieldName="title" returnType="text">Feature.Search.MyTitleComputedField, Feature.Search</field> ... </fields> </documentOptions> |
Solr Query Analyzers
When you used standard Sitecore index configuration for English texts, your search query will be processed by Solr with several analyzers: tokenizer and filters. Different filters are applied to different languages, you can check them in your index schema and compare with language specific filters in Solr help.
You can additionally improve the results using synonyms, stop-words and word stemming protection. Let’s check following example in Solr query analyzer:
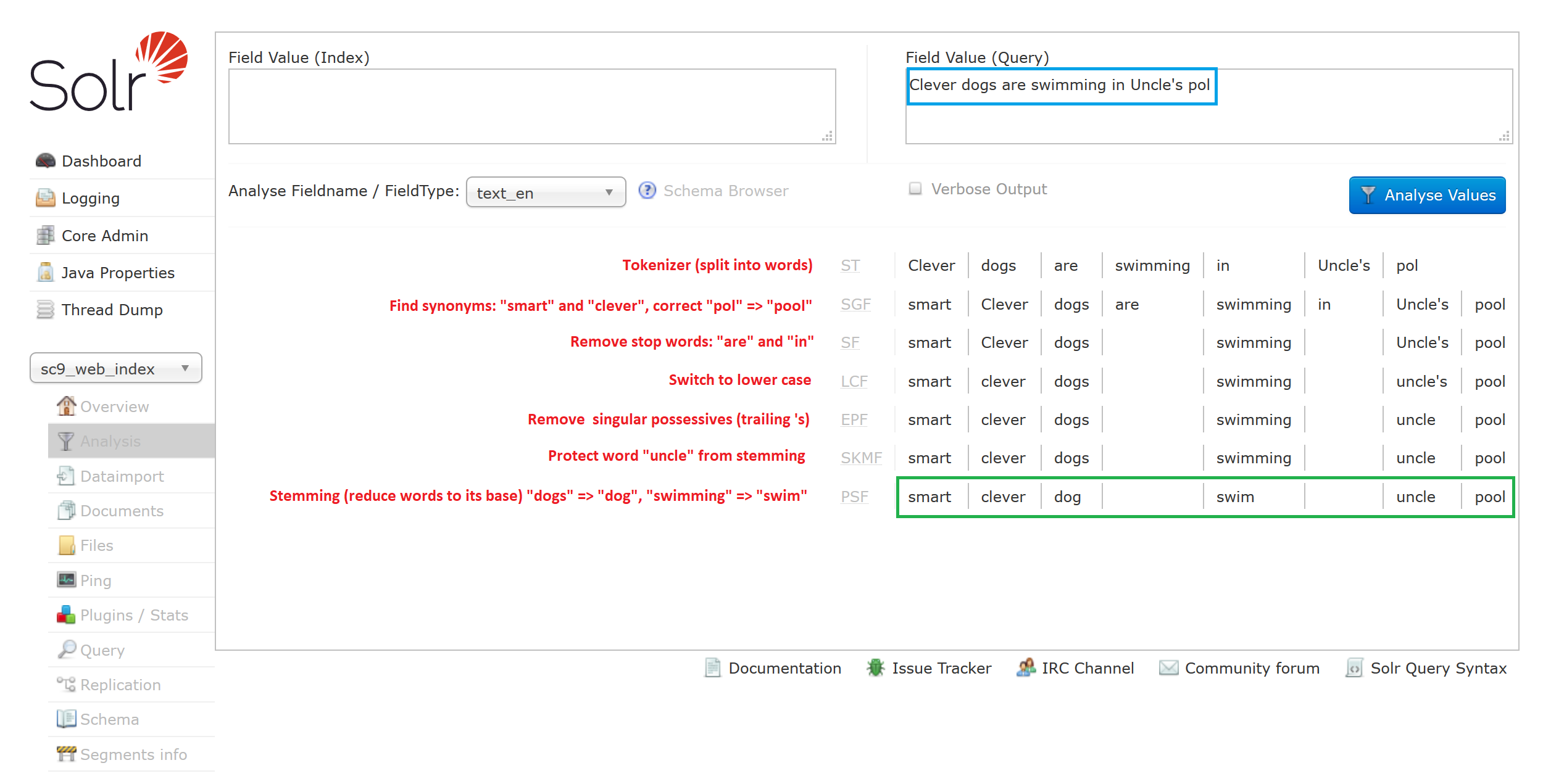 In example above we used:
In example above we used:
- default
{solr index root}\conf\lang\stopwords_en.txtto remove words like “are” and “in”. - edited
{solr index root}\conf\synonyms.txtto create synonyms and fix misspell:
smart,clever
pol => pool - edited
{solr index root}\conf\protwords.txtto prevent word “uncle” from stemming. Stemming is reducing words to its base, like “dogs” to “dog” or “swimming” to “swim”.
In the end, from our initial query “Clever dogs are swimming in Uncle’s pol” Solr will search for: smart, clever, dog, swim, uncle, pool.
Managed Resources via REST API
Instead of editing the text files, you can use REST API exposed by Solr to manage synonyms and stop-words, so you can build, for example a visual tool for your content authors to edit them inside Sitecore. To use REST API you have to update index configuration for stop-words and synonyms (you do it independently for each language):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <!--<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>--> <filter class="solr.ManagedStopFilterFactory" managed="english" /> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.EnglishPossessiveFilterFactory"/> <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/> <filter class="solr.PorterStemFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <!--<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>--> <filter class="solr.ManagedSynonymGraphFilterFactory" managed="english" /> <!--<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>--> <filter class="solr.ManagedStopFilterFactory" managed="english" /> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.EnglishPossessiveFilterFactory"/> <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/> <filter class="solr.PorterStemFilterFactory"/> </analyzer> </fieldType> |
Afterwards your synonyms and stop-words will be managed via service endpoints:
https://{solr-host}:{port}/solr/{index}/schema/analysis/stopwords/english
and:
https://{solr-host}:{port}/solr/{index}/schema/analysis/synonyms/english
To learn more about Solr REST API check Managed Resources section in Solr help page.
Solr Indexing Analyzers
Similar analysis happens during the indexing, but keep in mind that in default Sitecore index configuration some filters (like synonyms) are not applied during indexing of the content (compare filters in schema for analyzer type="index" and "query").
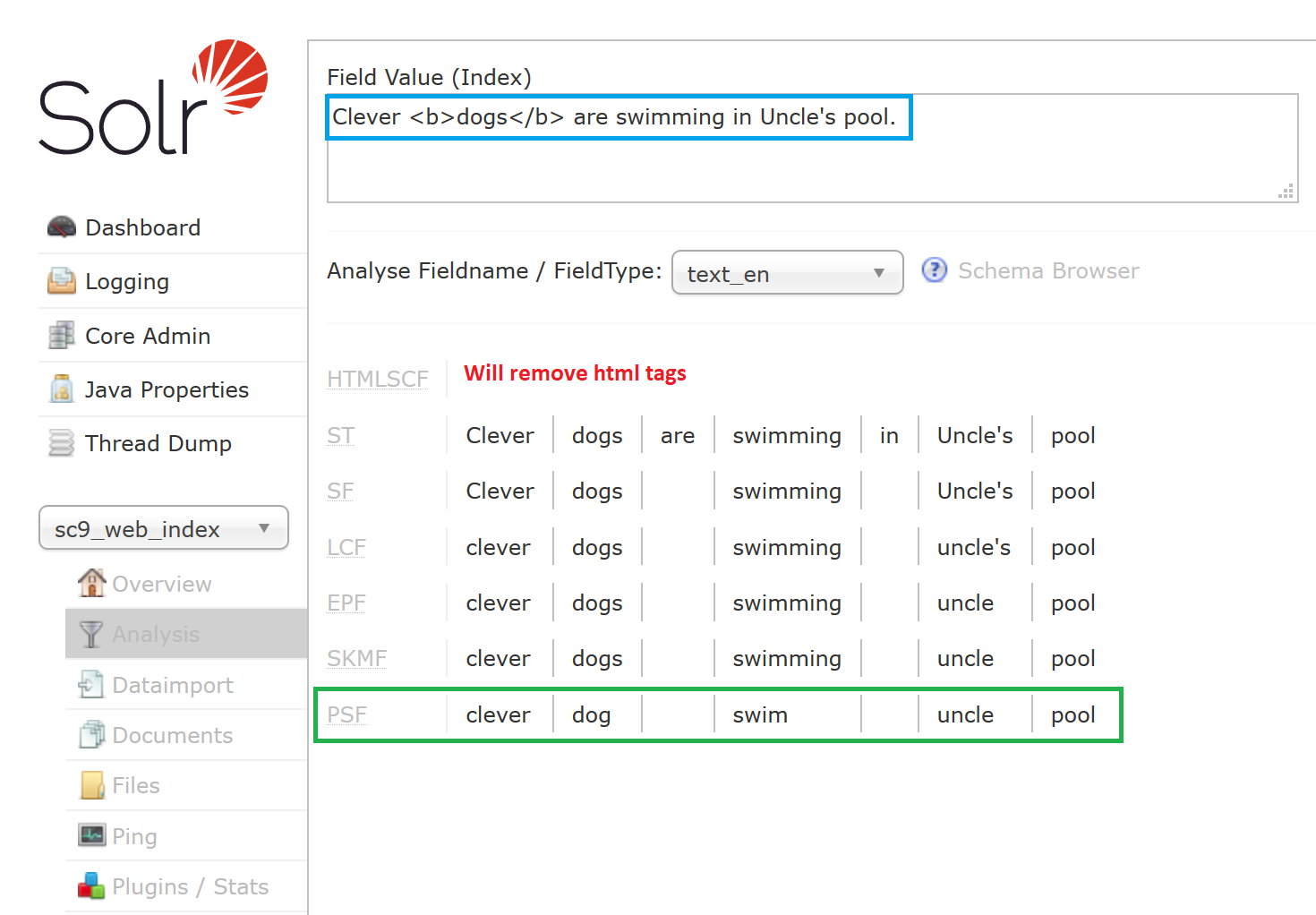
To improve indexing the content from Rich Text fields you may consider adding solr.HTMLStripCharFilterFactory, which will clean up HTML content for you, by removing HTML tags or scripts from the text. To enable it, you need to edit field type configuration in your schema:
|
1 2 3 4 5 6 7 8 |
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <charFilter class="solr.HTMLStripCharFilterFactory"/> <tokenizer class="solr.StandardTokenizerFactory"/> .... </analyzer> ... </fieldType> |
Afterwards your content should be indexed without the HTML tags:
Conclusions
Don’t be afraid to explore Solr filters, many of them will save you development time, or improve end-user experience. For multi-language sites check language specific factories and apply filters which are available for your language.
This is first part of my blog series about improving your Solr search, in the next part I will cover content tagging, search boosting, misspelling handling and index configuration best practices.